

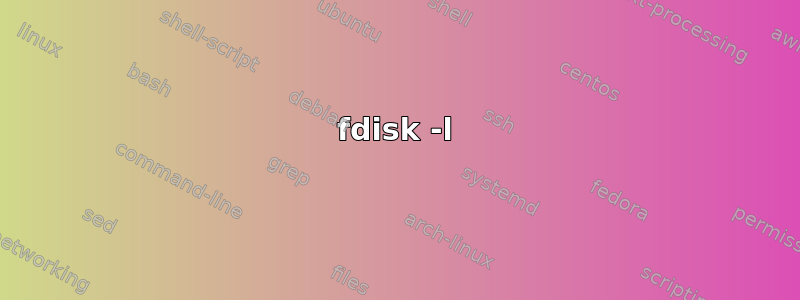
今天晚上我尝试将 mdadm raid 1 阵列移动到另一个系统。
我从一个系统中取出 2 个 SSD 并将它们放入另一个系统中,然后启动该系统。
我打开 gparted 检查磁盘显示的内容。它们显示为空白(未分配)驱动器。
然后我关闭了该系统并将驱动器移回原始系统并启动。
sudo mdadm --assemble --scan --verbose
sdg报告称在或上未发现 raid 超级块sgh,而我预计数据就在此处。
我认为这应该是一个相当简单的过程,但我现在不确定该怎么做。
任何帮助都将不胜感激,这很重要,我不会丢失这些驱动器上的数据......
这是(近似)输出sudo mdadm --misc --examine /dev/sd[efgh]
sde/sdf 报告预期输出,以Magic a92b4efc...开头,然后打印有关此 raid 1 阵列的一堆信息。
sdg/h 只需生产mbr magic aa55然后partition[0]: 1953525167 sectors at 1 (type ee)
我真的不知道这意味着什么,但我从另一个系统遇到的问题中感觉到 mdadm raid 信息和 gpt 分区表之间存在冲突?我的猜测对吗?如果对,我该怎么办?也许在降级状态下组装 raid,看看是否可以读取数据?
fdisk -l
sde/f化妆md1,md0缺少-应该sdg/h。
Disk /dev/sde: 931.5 GiB, 1000207286272 bytes, 1953529856 sectors
Disk model: WDC WDS100T2G0A-
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/md1: 931.4 GiB, 1000072019968 bytes, 1953265664 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sdf: 931.5 GiB, 1000207286272 bytes, 1953529856 sectors
Disk model: WDC WDS100T2G0A-
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sdg: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 860
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 76628399-779F-47D5-BF40-91930ECC85C8
Disk /dev/sdh: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Samsung SSD 860
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 0A316DF5-1431-44D5-8328-16960E7206B5
答案1
如果有人和我的情况一样,你可以试试这个
关闭系统,移除两个驱动器中的一个,然后重新启动。
为什么要移除 raid 1 阵列中 2 个驱动器中的 1 个?如果您彻底搞砸了,您将移除一个设备,因此希望您可以尝试使用该驱动器的替代方法,而不是摧毁镜像的两个成员。
sudo mdadm --create --verbose --force /dev/md0 --level=1 --raid-devices=1 /dev/sdg
这就是我认为这一方法有效的原因。
我记得我创建了一个镜像对,但在创建阵列之前,我没有执行将驱动器清零/将(分区)超级块清零的步骤。我相信我的 mdadm.conf 文件和更新 initramfs ( sudo update-initramfs -u) 可以防止这对驱动器遇到其所在系统的任何问题。我怀疑 gparted 或 fsck(或者可能是其他程序)检测到问题,因为 gpt 分区方案和 mdadm raid 超级块之间存在一些混淆,并且任何接触驱动器的工具都会用某种 gpt 块覆盖 mdadm 超级块。
无论如何 - 我在另一个系统上也遇到过类似的问题,这个问题是由重新启动该系统引起的,所以我打赌这个问题是类似的。(确实是这样的。)将这些驱动器移动到新系统会导致同样的问题。
我不太明白原因,只知道解决方案。
如果你遇到这种情况,我建议你创建一个新的 RAID 对,并将超级块清零第一的然后执行常规的 mdadm 创建过程。然后将数据从恢复模式(使用上面给出的行创建)复制到这个新的 raid,然后验证内容是否相同,然后丢弃这个“不稳定阵列”的内容。
要验证内容,请执行以下操作
find . -type f -exec sha256sum {} \; | sort > ~/sums.txt
diff ~/sums1.txt ~/sums2.txt