


我安装了全新的 CentOS 6.5,其中有两个 1TB Western Digital Black 硬盘(安装到 /mnt/data),使用 mdadm 组成 raid 1,通过安装程序配置。不幸的是,整个系统内核时不时地会崩溃,并出现类似以下的痕迹:

有诊断或修复此问题的提示吗?非常感谢!
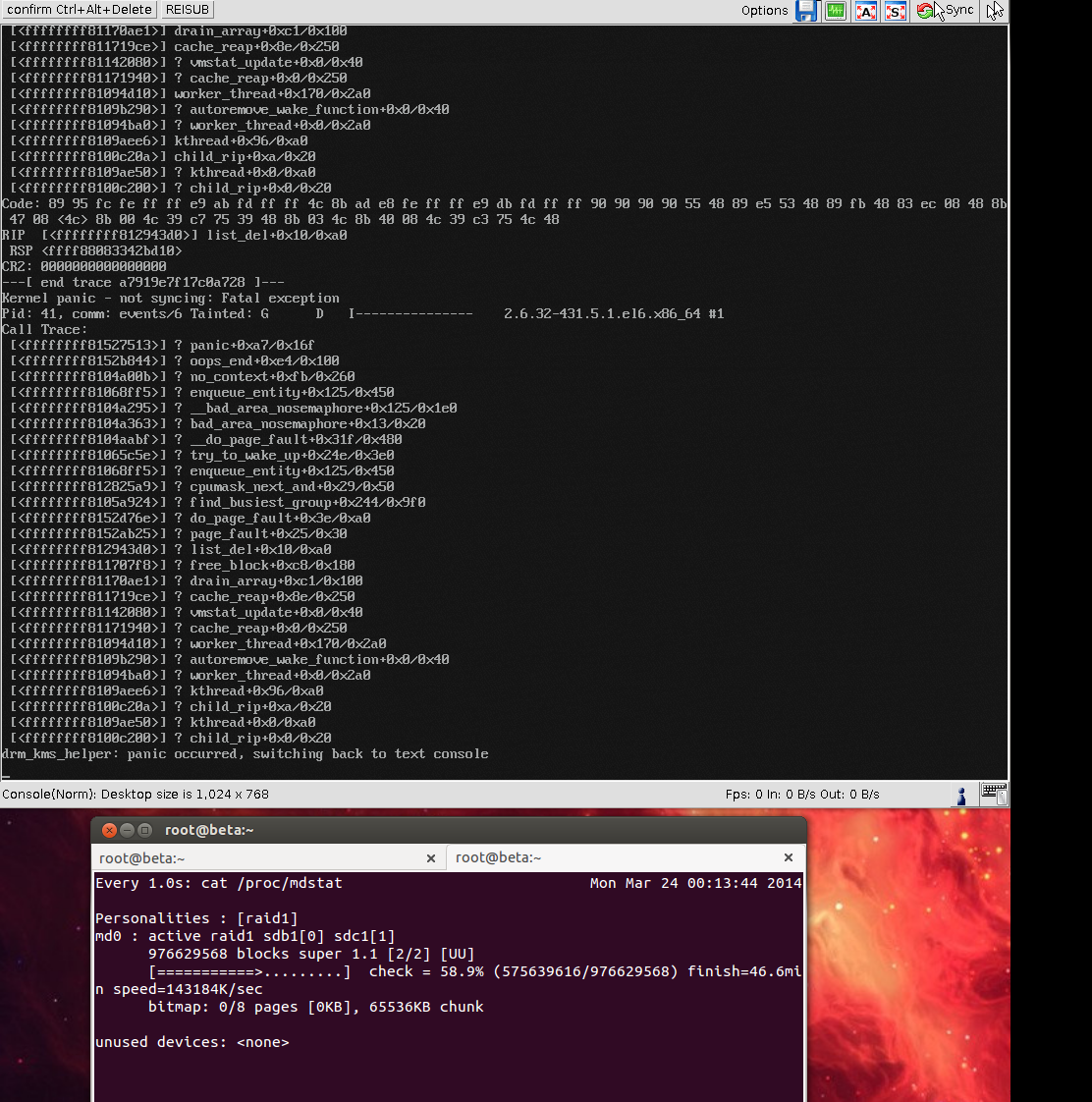
编辑:看来这发生在突袭数据检查发生的同时: 编辑2:最后两次事故都发生在周日凌晨 1 点刚过,数据检查也发生在同一时间。
Mar 23 01:00:02 beta kernel: md: data-check of RAID array md0
Mar 23 01:00:02 beta kernel: md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
Mar 23 01:00:02 beta kernel: md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for data-check.
Mar 23 01:00:02 beta kernel: md: using 128k window, over a total of 976629568k.
/proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc1[1] sdb1[0]
976629568 blocks super 1.1 [2/2] [UU]
bitmap: 0/8 pages [0KB], 65536KB chunk
unused devices: <none>
mdadm -D
/dev/md0:
Version : 1.1
Creation Time : Fri Mar 7 16:07:17 2014
Raid Level : raid1
Array Size : 976629568 (931.39 GiB 1000.07 GB)
Used Dev Size : 976629568 (931.39 GiB 1000.07 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Sun Mar 23 03:36:59 2014
State : active
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Name : beta.fmt2.spigot-servers.net:0 (local to host beta.fmt2.spigot-servers.net)
UUID : 89a86538:f6162473:d5e0524c:b80566d6
Events : 1728
Number Major Minor RaidDevice State
0 8 17 0 active sync /dev/sdb1
1 8 33 1 active sync /dev/sdc1
编辑3:不同的崩溃,发生在强制重新同步/检查期间,并且内存测试顺利通过了 4 次: http://files.md-5.net/s/X3Hi.png
{kind=link}
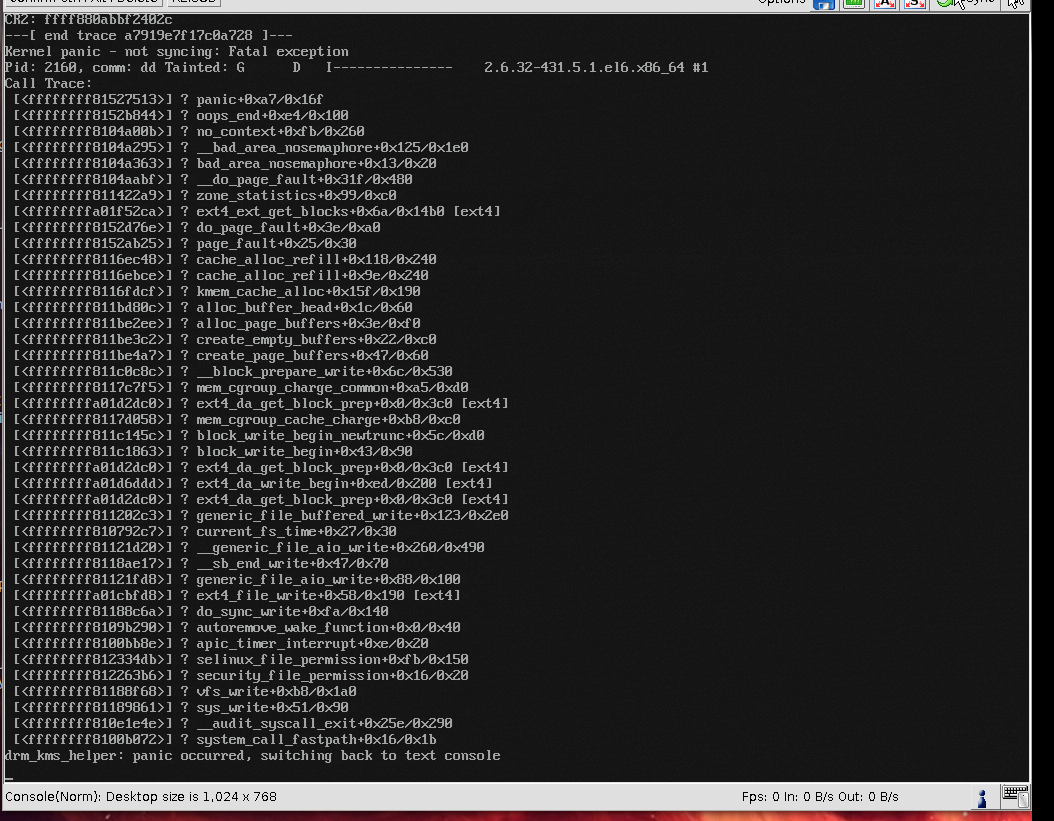
编辑4:即使 dd 也会导致崩溃:http://files.md-5.net/s/hba2.png
{kind=link}
编辑5:SSD 通过了 dd 严酷测试,我想这意味着我将尝试使用没有 raid 的驱动器。
答案1
这可能表明磁盘硬件状态:
[root@ninja ~]$ /etc/rc.d/init.d/smartd start
[root@ninja ~]$ smartctl --all /dev/sdc | grep 'health'
SMART overall-health self-assessment test result: PASSED
[root@ninja ~]$ smartctl --all /dev/sdb | grep 'health'
SMART overall-health self-assessment test result: PASSED