


我在 AWS 上有一个 t2.micro EC2 实例,它在 Docker 中运行两个实验性的 REST 服务和 MySQL,接收来自 EC2 外部源的 REST 调用。一个实例在端口 81 上使用 HTTP,另一个在端口 443 上使用 HTTPS。
偶尔,根据 CloudWatch,CPU 会猛增至 100%,但网络或磁盘活动并没有太多激增。结果就是我每次都无法通过 SSH 进入此实例。
我的本地日志到文本文件没有显示太多 REST 服务器正在执行的操作。可能是什么原因造成的?我该如何开始诊断问题?如果我无法通过 SSH 进入这台机器,是否有可能知道哪个进程正在占用 CPU 周期?
编辑:顺便说一句,当这一切发生时,EC2 控制台确实说实例仍然处于绿色状态 - 正在运行。
答案1
有几个想法,不确定是否能完美发挥作用,但如果没有其他人有更好的想法,它们可能会有所帮助。
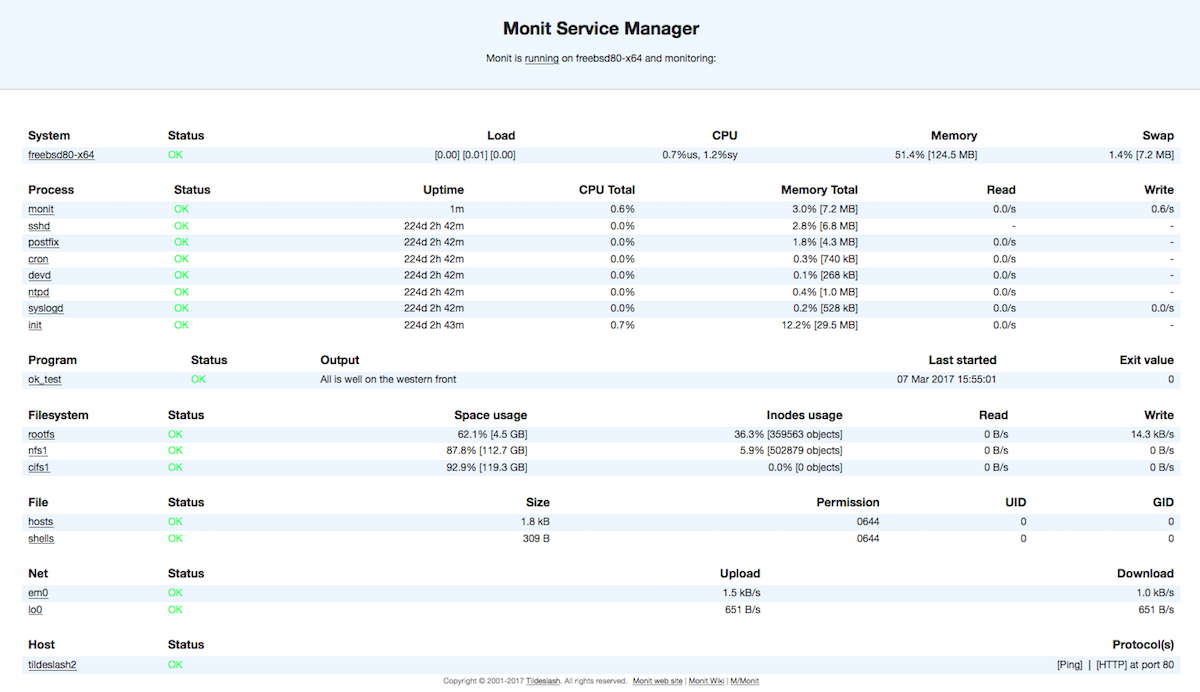
尝试监控。按照文档配置它来监控关键进程,保持页面打开,页面每 60 秒刷新一次。示例如下。
通过 SSH 保持登录状态并运行 top。
使用系统管理器 会话管理器另一种 SSH 连接方式。它使用 https 从实例到 AWS 基础设施来访问机器,并为您提供一个 ssh 控制台,当标准 ssh 不起作用时,它可能起作用。它是设置起来有点棘手,您必须正确设置安全组和 VPC 端点,这可能需要一些时间。我已经使用 CloudFormation 实现了自动化,但我无法轻松地将其从模板中提取出来,有人会创建一个您可以使用的模板 - 请查看 git hub。
答案2
有多种方法可以解决这个问题:
- 启用详细的 CloudWatch 监控以获取更多见解,从而了解正在发生的事情(我的假设是内存不足,然后 OOM killer 启动)
- 通过导航至“操作”->“实例设置”->“获取系统日志”来检查该实例的系统日志,以了解实际发生的情况
- 使用更大的实例类型,这样它就不会耗尽资源,并且可以让您有时间分析消费者是什么,直到它再次变得不稳定。