


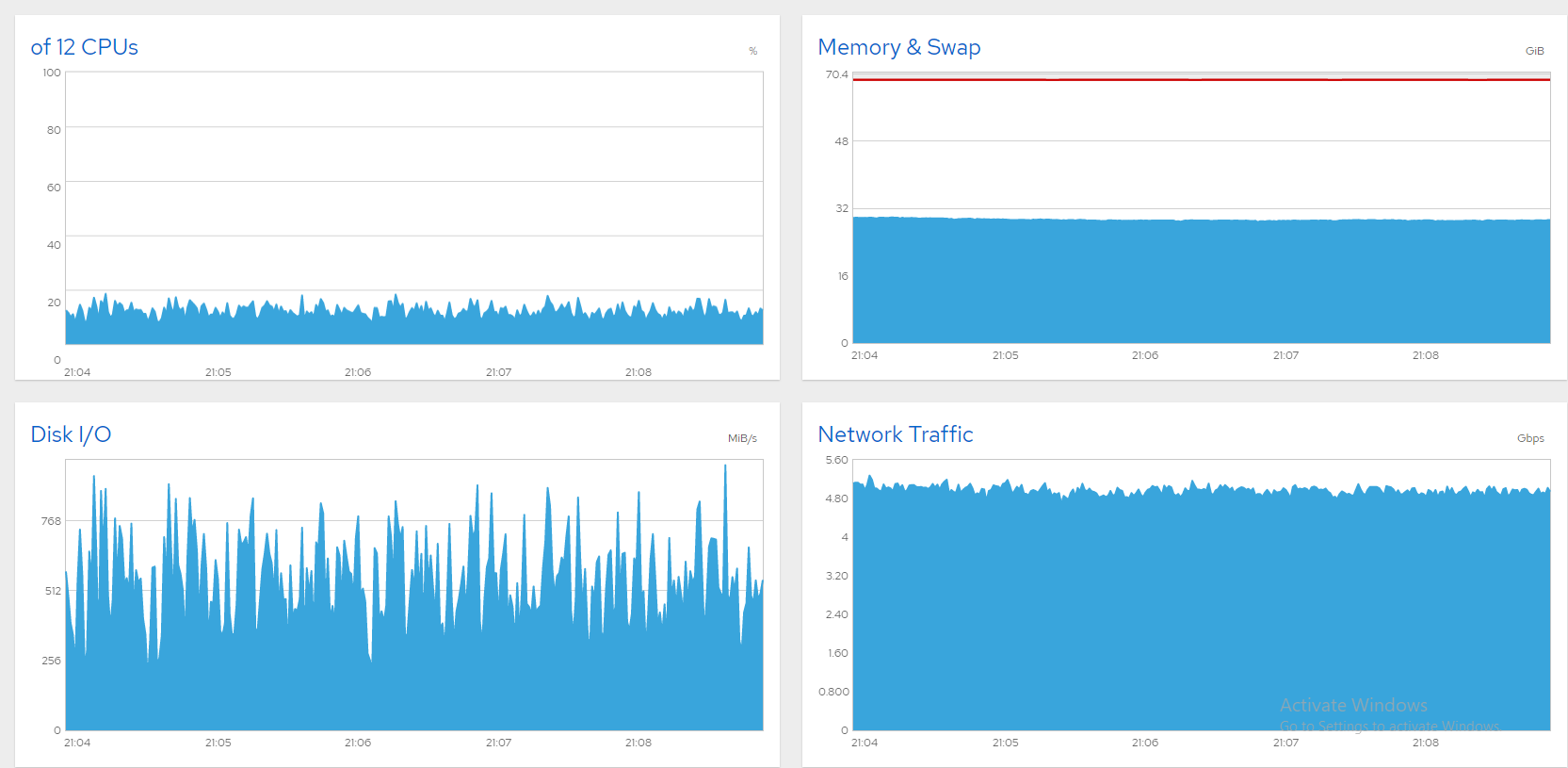
简单介绍一下背景;我有一台 10Gbit 文件服务器,有六个数据 SSD,运行 CentOS 8,我正在努力使线路饱和。如果我将带宽限制在 5 或 6Gbps,一切都很好。以下是 Cockpit 的一些图表,显示一切正常(约 850 个并发用户,5Gbps 上限)。
不幸的是,当我将带宽推得更高时,带宽会大幅波动。通常,这是磁盘(或 SATA 卡)饱和的标志,在 Windows 机器上,我是这样解决的:
- 打开“资源监视器”。
- 选择“磁盘”选项卡。
- 查看“队列长度”图表。任何队列长度稳定超过 1 的磁盘/raid 都是瓶颈。升级它或减少其负载。
现在我在 CentOS 8 服务器中看到了这些症状,但我该如何找出罪魁祸首呢?我的 SATA SSD 被分成三个软件 RAID0 阵列,如下所示:
# cat /proc/mdstat
Personalities : [raid0]
md2 : active raid0 sdg[1] sdf[0]
7813772288 blocks super 1.2 512k chunks
md0 : active raid0 sdb[0] sdc[1]
3906764800 blocks super 1.2 512k chunks
md1 : active raid0 sdd[0] sde[1]
4000532480 blocks super 1.2 512k chunks`
iostat波动很大,并且通常具有较高的 %iowait。如果我没看错的话,这似乎表明 md0 (sdb+sdc) 的负载最大。但这是一个瓶颈吗?毕竟,%util 远没有达到 100。
# iostat -xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
7.85 0.00 35.18 50.02 0.00 6.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 106.20 57.20 0.89 0.22 3.20 0.00 2.93 0.00 136.87 216.02 26.82 8.56 3.99 0.92 14.96
sde 551.20 0.00 153.80 0.00 65.80 0.00 10.66 0.00 6.75 0.00 3.44 285.73 0.00 0.64 35.52
sdd 571.60 0.00 153.77 0.00 45.80 0.00 7.42 0.00 6.45 0.00 3.40 275.48 0.00 0.63 35.98
sdc 486.60 0.00 208.93 0.00 305.40 0.00 38.56 0.00 20.60 0.00 9.78 439.67 0.00 1.01 49.10
sdb 518.60 0.00 214.49 0.00 291.60 0.00 35.99 0.00 81.25 0.00 41.88 423.52 0.00 0.92 47.88
sdf 567.40 0.00 178.34 0.00 133.60 0.00 19.06 0.00 17.55 0.00 9.68 321.86 0.00 0.28 16.08
sdg 572.00 0.00 178.55 0.00 133.20 0.00 18.89 0.00 17.63 0.00 9.81 319.64 0.00 0.28 16.00
dm-0 5.80 0.80 0.42 0.00 0.00 0.00 0.00 0.00 519.90 844.75 3.69 74.62 4.00 1.21 0.80
dm-1 103.20 61.40 0.40 0.24 0.00 0.00 0.00 0.00 112.66 359.15 33.68 4.00 4.00 0.96 15.86
md1 1235.20 0.00 438.93 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 363.88 0.00 0.00 0.00
md0 1652.60 0.00 603.88 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 374.18 0.00 0.00 0.00
md2 1422.60 0.00 530.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 381.72 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
5.14 0.00 22.00 72.86 0.00 0.00
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 34.00 37.40 0.15 0.15 5.20 0.00 13.27 0.00 934.56 871.59 64.34 4.61 4.15 0.94 6.74
sde 130.80 0.00 36.14 0.00 15.00 0.00 10.29 0.00 5.31 0.00 0.63 282.97 0.00 0.66 8.64
sdd 132.20 0.00 36.35 0.00 14.40 0.00 9.82 0.00 5.15 0.00 0.61 281.57 0.00 0.65 8.62
sdc 271.00 0.00 118.27 0.00 176.80 0.00 39.48 0.00 9.52 0.00 2.44 446.91 0.00 1.01 27.44
sdb 321.20 0.00 116.97 0.00 143.80 0.00 30.92 0.00 12.91 0.00 3.99 372.90 0.00 0.91 29.18
sdf 340.20 0.00 103.83 0.00 71.80 0.00 17.43 0.00 12.17 0.00 3.97 312.54 0.00 0.29 9.90
sdg 349.20 0.00 104.06 0.00 66.60 0.00 16.02 0.00 11.77 0.00 3.94 305.14 0.00 0.29 10.04
dm-0 0.00 0.80 0.00 0.01 0.00 0.00 0.00 0.00 0.00 1661.50 1.71 0.00 12.00 1.25 0.10
dm-1 38.80 42.20 0.15 0.16 0.00 0.00 0.00 0.00 936.60 2801.86 154.58 4.00 4.00 1.10 8.88
md1 292.60 0.00 111.79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 391.22 0.00 0.00 0.00
md0 951.80 0.00 382.39 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 411.40 0.00 0.00 0.00
md2 844.80 0.00 333.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 403.71 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
同时,服务器性能非常糟糕。通过 SSH 进行的每个按键都需要几秒钟才能注册,GNOME 桌面几乎没有响应,用户报告连接中断。我会显示 Cockpit 图表,但登录超时。限制带宽效果很好,但我想解锁其余部分。那么我该如何识别瓶颈?我很乐意听取一些建议!
答案1
罪魁祸首是 sda,即 CentOS 的磁盘。大多数证据都指向那里。正如某人评论的那样(似乎已删除),sda、dm-0 和 dm-1 上的等待时间看起来可疑。果然,dm-0(根)和 dm-1(交换)也在 sda 上。观察 iotop 的运行,瓶颈似乎是由 Gnome 活动的快速闪烁引发的,随后 kswapd(交换)阻塞了工作。使用“init 3”关闭 Gnome 确实有所改善,但如此强大的机器不可能因空闲的登录屏幕而瘫痪。SMART 还报告 sda 上有 8000 多个坏扇区。我猜其中许多都在交换空间中,导致交换使系统瘫痪。
一个想法是将交换移至另一个磁盘,但替换 sda 似乎更实用。我开始使用 CloneZilla 进行磁盘克隆,但估计需要 3 个小时,全新安装会更快,所以我选择了那个。现在服务器运行良好!以下屏幕截图显示 1300 多个文件同时通过 8Gbps 传输,非常稳定。问题解决了!
