


我的目标是通过一些 iptables 规则来观察网络流量的流动。但是,iptables 似乎没有像我预期的那样工作。似乎作为请求响应的数据包不遵守 NAT 表规则。
首先,我创建了一些记录syslog匹配数据包的规则。以下是我的NAT表格规则:
# iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
-A PREROUTING -d 10.0.0.1/32 -j LOG --log-prefix "+++ nat, preroute +++"
-A OUTPUT -d 10.0.0.2/32 -j LOG --log-prefix "+++ nat, output +++"
-A POSTROUTING -d 10.0.0.2/32 -j LOG --log-prefix "+++ nat, postrouting ++++"
以下是我的filter餐桌规则:
# iptables -t filter -S
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
-N DOCKER-ISOLATION-STAGE-1
-N DOCKER-ISOLATION-STAGE-2
-N DOCKER-USER
-A INPUT -d 10.0.0.1/32 -j LOG --log-prefix "+++ filter, input +++"
-A OUTPUT -d 10.0.0.2/32 -j LOG --log-prefix "++++ filter, output ++++"
raw,表格mangle也security很清楚:
# iptables -t raw -S
-P PREROUTING ACCEPT
-P OUTPUT ACCEPT
# iptables -t mangle -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
# iptables -t security -S
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
为了测试我的规则,我使用以下脚本创建了一个网络命名空间。它创建了一个网络命名空间以及一对 veth 接口,其中一个对等体连接到网络命名空间:
#!/bin/bash
set -ex
ip netns add net1
ip link add veth1 type veth peer veth2 netns net1
ip link set veth1 up
ip netns exec net1 ip link set veth2 up
ip netns exec net1 ip link set lo up
ip addr add 10.0.0.1/24 dev veth1
ip netns exec net1 ip addr add 10.0.0.2/24 dev veth2
然后我使用命名空间veth中的接口ping 我的本地主机net1:
# ip netns exec net1 ping 10.0.0.1
PING 10.0.0.1 (10.0.0.1) 56(84) bytes of data.
64 bytes from 10.0.0.1: icmp_seq=1 ttl=64 time=0.106 ms
64 bytes from 10.0.0.1: icmp_seq=2 ttl=64 time=0.088 ms
64 bytes from 10.0.0.1: icmp_seq=3 ttl=64 time=0.085 ms
根据这个图像,这是其中的一部分博客,我期望看到以下消息日志syslog:
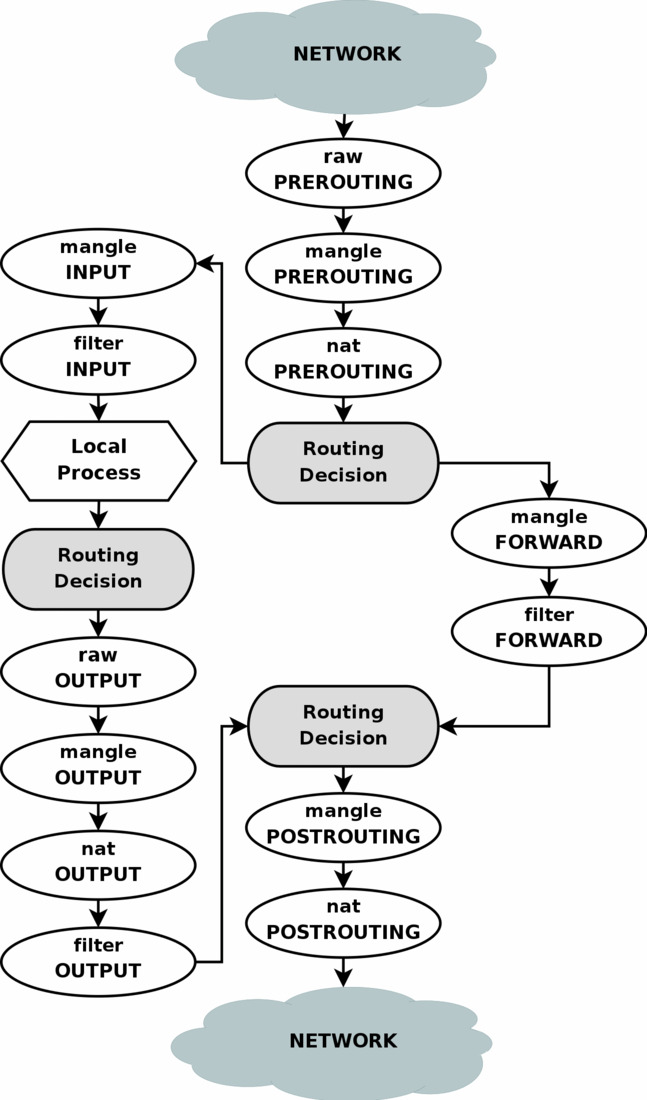{kind=link}
+++ nat, preroute +++ -> for first packet destined to 10.0.0.1
+++ filter, input +++ -> for first packet destined to 10.0.0.1
+++ nat, output +++ -> for first response packet destined to 10.0.0.2
+++ nat, postrouting ++++ -> for first response packet destined to 10.0.0.2
但是,syslog日志有所不同:
May 1 10:46:35 safdarian-Legion-5-15ITH6 kernel: [ 4165.810315] +++ nat, preroute +++IN=veth1 OUT= MAC=1a:31:55:32:60:0d:2e:bb:08:2b:8b:5e:08:00 SRC=10.0.0.2 DST=10.0.0.1 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=10280 DF PROTO=ICMP TYPE=8 CODE=0 ID=37055 SEQ=1
May 1 10:46:35 safdarian-Legion-5-15ITH6 kernel: [ 4165.810327] +++ filter, input +++IN=veth1 OUT= MAC=1a:31:55:32:60:0d:2e:bb:08:2b:8b:5e:08:00 SRC=10.0.0.2 DST=10.0.0.1 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=10280 DF PROTO=ICMP TYPE=8 CODE=0 ID=37055 SEQ=1
May 1 10:46:35 safdarian-Legion-5-15ITH6 kernel: [ 4165.810341] ++++ filter, output ++++IN= OUT=veth1 SRC=10.0.0.1 DST=10.0.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=27366 PROTO=ICMP TYPE=0 CODE=0 ID=37055 SEQ=1
May 1 10:46:36 safdarian-Legion-5-15ITH6 kernel: [ 4166.813517] +++ filter, input +++IN=veth1 OUT= MAC=1a:31:55:32:60:0d:2e:bb:08:2b:8b:5e:08:00 SRC=10.0.0.2 DST=10.0.0.1 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=10332 DF PROTO=ICMP TYPE=8 CODE=0 ID=37055 SEQ=2
May 1 10:46:36 safdarian-Legion-5-15ITH6 kernel: [ 4166.813538] ++++ filter, output ++++IN= OUT=veth1 SRC=10.0.0.1 DST=10.0.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=27433 PROTO=ICMP TYPE=0 CODE=0 ID=37055 SEQ=2
May 1 10:46:37 safdarian-Legion-5-15ITH6 kernel: [ 4167.837538] +++ filter, input +++IN=veth1 OUT= MAC=1a:31:55:32:60:0d:2e:bb:08:2b:8b:5e:08:00 SRC=10.0.0.2 DST=10.0.0.1 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=10508 DF PROTO=ICMP TYPE=8 CODE=0 ID=37055 SEQ=3
May 1 10:46:37 safdarian-Legion-5-15ITH6 kernel: [ 4167.837558] ++++ filter, output ++++IN= OUT=veth1 SRC=10.0.0.1 DST=10.0.0.2 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=27527 PROTO=ICMP TYPE=0 CODE=0 ID=37055 SEQ=3
有人能解释一下为什么吗?
答案1
iptables NAT 是有状态的并且是按流而不是按包。
只有第一的流的数据包(即属于未知流的数据包)通过“nat”表发送 - 所有后续数据包都会绕过它,因为它们被 conntrack 1子系统识别,该子系统会自动应用相同的转换或反向转换进行回复。
因此匹配的“Echo Reply”数据包-d 10.0.0.2/32永远不会到达“POSTROUTING”链(或者“PREROUTING” 2),因为它被识别为属于现有的 ICMP 流并自动跳过整个“nat”表。
(“流”直接映射到 TCP 或 SCTP 中的连接,但对于无连接的 L4 协议(如 UDP 或 ICMP),它们是隐式建立的,具有某种超时;例如,同一 src:sport⇆dst:dport 之间的所有 UDP 数据包都是同一流的一部分,直到它过期。)
您可以使用conntrack -L来查看流表;请注意它有两组源/目标对,即原始对和“回复对”。(例如,如果您要在预路由中应用出站 DNAT,则入站回复数据包将与“回复对”字段匹配,并将自动进行相应的 SNAT。)
1--state ESTABLISHED这与 iptables 过滤规则或ct statenftables 规则中常见的实现完全相同的 conntrack 。
2您的规则(包含这些特定-d匹配)似乎是在假设 PREROUTING 仅适用于出站数据包而 POSTROUTING 仅适用于入站数据包的情况下编写的。事实并非如此 - 所有数据包都将穿越两个都鏈。