


我有两个配置非常相似的虚拟服务器:Debian bullseye(测试版)、5.6.0 内核、512 MB RAM。它们都运行类似的工作负载:MySQL、PowerDNS、WireGuard、dnstools.ws worker 和用于监控的 Netdata。
在其中一台服务器上,不可回收的 slab 内存随着时间的推移呈线性增长,直到达到最大值(当服务器的内存分配率为 100%时):
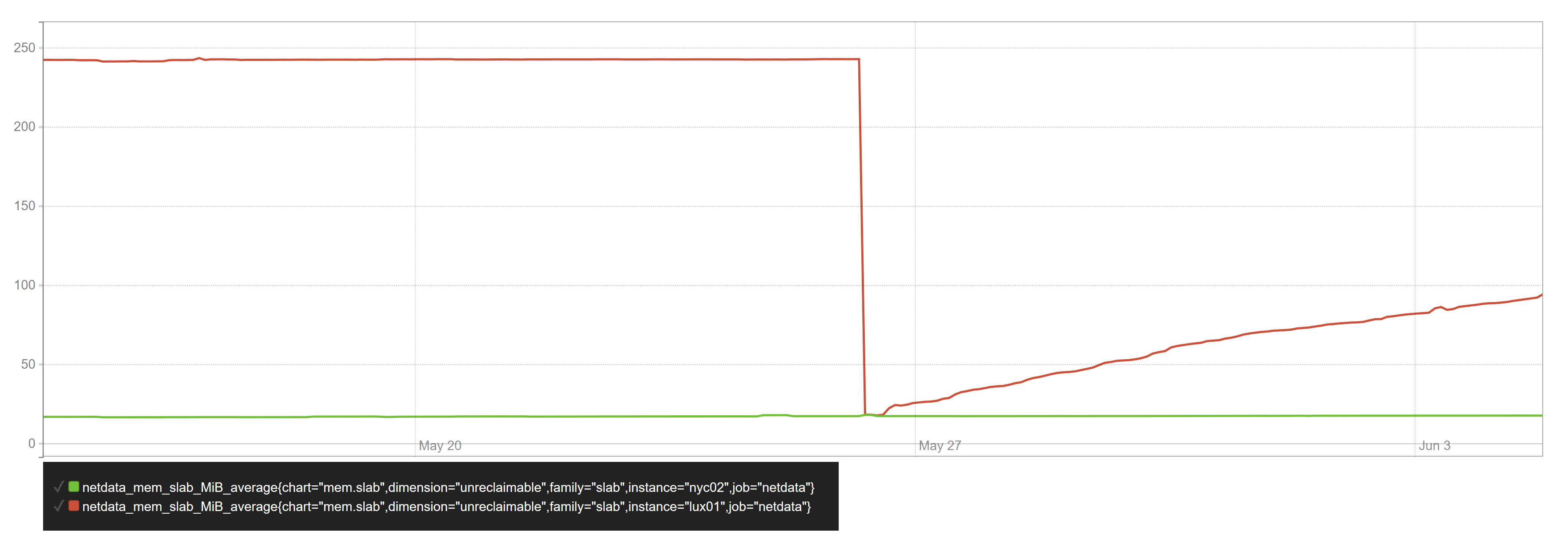
当我重新启动 VPS 时出现了掉线的情况。
slabtop在坏服务器上:
Active / Total Objects (% used) : 1350709 / 1363259 (99.1%)
Active / Total Slabs (% used) : 25358 / 25358 (100.0%)
Active / Total Caches (% used) : 96 / 124 (77.4%)
Active / Total Size (% used) : 113513.48K / 117444.72K (96.7%)
Minimum / Average / Maximum Object : 0.01K / 0.09K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1173504 1173504 100% 0.06K 18336 64 73344K kmalloc-64
22512 18020 80% 0.19K 1072 21 4288K dentry
16640 16640 100% 0.12K 520 32 2080K kernfs_node_cache
15872 15872 100% 0.01K 31 512 124K kmalloc-8
15616 15616 100% 0.03K 122 128 488K kmalloc-32
11904 11283 94% 0.06K 186 64 744K anon_vma_chain
10218 9953 97% 0.59K 786 13 6288K inode_cache
9867 8354 84% 0.10K 253 39 1012K buffer_head
9272 9111 98% 0.20K 488 19 1952K vm_area_struct
6808 6808 100% 0.09K 148 46 592K anon_vma
5632 5632 100% 0.02K 22 256 88K kmalloc-16
5145 5145 100% 0.19K 245 21 980K kmalloc-192
4845 3758 77% 1.05K 651 15 10416K ext4_inode_cache
4830 3795 78% 0.57K 347 14 2776K radix_tree_node
4144 3380 81% 0.25K 259 16 1036K filp
3825 3825 100% 0.05K 45 85 180K ftrace_event_field
3584 3072 85% 0.03K 28 128 112K ext4_pending_reservation
2448 2448 100% 0.04K 24 102 96K ext4_extent_status
2368 1058 44% 0.06K 37 64 148K vmap_area
slabtop在好的服务器上:
Active / Total Objects (% used) : 236705 / 264128 (89.6%)
Active / Total Slabs (% used) : 7119 / 7119 (100.0%)
Active / Total Caches (% used) : 96 / 124 (77.4%)
Active / Total Size (% used) : 31422.39K / 36341.06K (86.5%)
Minimum / Average / Maximum Object : 0.01K / 0.14K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
35551 27123 76% 0.05K 487 73 1948K buffer_head
30368 19821 65% 0.12K 949 32 3796K dentry
19872 19872 100% 0.12K 621 32 2484K kmalloc-128
18666 18666 100% 0.08K 366 51 1464K kernfs_node_cache
17664 17664 100% 0.02K 69 256 276K kmalloc-16
16128 16128 100% 0.03K 126 128 504K anon_vma_chain
15872 15872 100% 0.01K 31 512 124K kmalloc-8
11136 11136 100% 0.03K 87 128 348K kmalloc-32
10330 10112 97% 0.38K 1033 10 4132K inode_cache
9945 9597 96% 0.10K 255 39 1020K vm_area_struct
7798 4753 60% 0.71K 710 11 5680K ext4_inode_cache
7008 7008 100% 0.05K 96 73 384K anon_vma
5859 5668 96% 0.19K 279 21 1116K filp
5120 2894 56% 0.03K 40 128 160K jbd2_revoke_record_s
4680 3510 75% 0.30K 360 13 1440K radix_tree_node
4224 4224 100% 0.03K 33 128 132K vmap_area
3392 3392 100% 0.06K 53 64 212K kmalloc-64
3264 3264 100% 0.04K 32 102 128K jbd2_inode
3145 3145 100% 0.05K 37 85 148K trace_event_file
值得注意的是,有一些东西分配很多板坯kmalloc-64。
我该如何调试导致这些分配的原因?
答案1
阅读了一些内核文档并发现我可以添加slub_debug=U到 GRUB 内核命令行来跟踪 slab 分配。
在两台服务器上执行此操作并重新启动它们之后,/sys/kernel/slab/kmalloc-64/alloc_calls“坏”服务器上出现了一个问题,而在“好”服务器上则完全不存在这个问题:
13212 kvm_async_pf_task_wake+0x6e/0x100 age=3329/480991/1729176 pid=0-13255
搜索了一下,我发现了一篇帖子,其中有人遇到了完全相同的问题:https://darkimmortal.com/debian-10-kernel-slab-memortal-leak/。这篇文章记录了添加到 Linux 命令行的解决方法no-kvmapf。不确定这是否会产生任何其他副作用。