


例子:
1:20 2:25 3:0.432 2:-17 10:12
我想替换所有字符串开始与2:到2:0。
输出:
1:20 2:0 3:0.432 2:0 10:12
答案1
使用sed:
sed -E 's/((^| )2:)[^ ]*/\10/g' in > out
此外,受到启发souravc 的回答, 如果有不是2:字符串开头后出现子字符串的概率不是包含前导子2:字符串(例如不是字符串的可能性1:202:25,以下缩短的命令将替换为1:202:0),该命令可能会缩短为:
sed -E 's/2:[^ ]*/2:0/g' in > out
命令 #1 / #2 细分:
-E:sed将该模式解释为 ERE(扩展正则表达式)模式;> out: 重定向stdout到out;
sed命令 #1 分解:
s:断言执行替换/:开始模式(:开始捕获组(:开始对允许的字符串进行分组^: 匹配行首|: 分隔第二个允许的字符串: 匹配一个字符):停止对允许的字符串进行分组2: 匹配一个2字符:: 匹配一个:字符):停止捕获组[^ ]*: 匹配任意数量的字符,而不是/:停止模式/开始替换字符串\1: 反向引用被第一个捕获组替换0: 添加一个0字符/:停止替换字符串/启动模式标志g:断言全局执行替换,即替换行中出现的每个模式
sed命令 #2 分解:
s:断言执行替换/:开始模式2: 匹配一个2字符:: 匹配一个:字符[^ ]*: 匹配任意数量的字符,而不是/:停止模式/开始替换字符串2:0:添加一个2:0字符串/:停止替换字符串/启动模式标志g:断言全局执行替换,即替换行中出现的每个模式
答案2
这行代码使用sed
sed -i.bkp 's/2:\([0-9]*\)\|2:\(-\)\([0-9]*\)/2:0/g' input_file
将要全局内联替换在同一目录中input_file保留一个名为的备份文件。input_file.bkp
可以使用扩展正则表达式进一步缩短此长度建议作者:kos,as
sed -ri.bkp 's/2:\-?[0-9]*/2:0/g' input_file
答案3
我会使用一个基本awk循环:
$ awk '{for (i=1; i<=NF; i++) $i~/^2:/ && $i="2:0"}1' file
1:20 2:0 3:0.432 2:0 10:12
这将循环遍历所有字段。只要其中一个字段以 开头2:,它就会将其全部替换为2:0。最后,1代表 True,这样就会打印出整行。
答案4
感谢@kos 提供的sed版本:
对方式进行一些小修改perl:
perl -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
回复:
perl -i -pe 's/((^|\s)2:)[^\s]*/${1}0/g' testdata
解释:
((^|\s)2:)[^\s]*
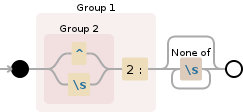
第一捕获组
((^|\s)2:)- 第二捕获组
(^|\s) 第一种方案:
^^断言字符串开头的位置第二种选择:
\s\s匹配任何空白字符[\r\n\t\f ]
2:与字符2:逐字匹配- 第二捕获组
[^\s]*匹配下面列表中不存在的单个字符量词:
*零次至无限次之间,尽可能多次,根据需要返回 [贪婪]\s匹配任何空白字符[\r\n\t\f ]
或者积极回顾,谢谢@steeldriver
perl -pe 's/(?<=2:)\S*/0/g' testdata
解释
(?<=2:)\S*
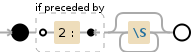
(?<=2:)正向后视 - 断言下面的正则表达式可以匹配2:匹配字符2: literally\S*匹配任何非空白字符[^\r\n\t\f ]量词:
*零次至无限次之间,尽可能多次,根据需要返回 [贪婪]